Хотелось бы начать первую статью с самого простого , базового — это распознавание рукописных символов с использованием готовой базы изображений MNIST , опустим такие подробности как дата создания , авторов и прочее , да бы описать самые необходимые инструменты .
И начну статью с известного нам онлайн интерпретатора https://colab.research.google.com/ , в нем будет протекать вся наша работа по обучению нейросети , инструмент позволяет нам подгружать все необходимые библиотеки без установки , а так же самые популярные базы , в том числе и MNIST , который мы и будем разбирать. Поехали !!!
Для начала нам необходимо подгрузить нашу базу изображений и необходимые библиотеки для ее обработки ( о них позже)
## from tensorflow.keras.datasets import mnist import matplotlib.pyplot as plt %matplotlib inline
Что в данном случае произошло.. , первым делом мы подгрузили библиотеку tensorflow обернутую в keras , простыми словами- эти библиотеки будут использоваться нами постоянно , они и содержат в себе весь необходимый функционал машинного обучения , они не единственные , но они мощные и популярные. Вторая строка — это инструмент — библиотека matplotlib необходимая нам для визуализации данных , чтобы мы наглядно видели изображения графиков , картинок и прочего графического содержимого , могли визуализировать данные. Третья строка %matplotlib inline позволяет нам отрисовывать графики прямо в редакторе.
Базу мы подгрузили , но прежде чем начать с ней работать , нам необходимо ее рассортировать на составляющие .
Что в себе содержит база mnist: это 4 списка , 4 массива ну или просто 4 блока с данными , кому как удобно.
- список картинок для обучения нейросети
- список правильных ответов соответствующие предыдущим картинкам
- список картинок для тестирования
- список правильных ответов для тестирования сети
## (X_train, Y_train), (X_test, Y_test) = mnist.load_data()
а вот и они:
- X_train
- Y_train
- X_test
- Y_test
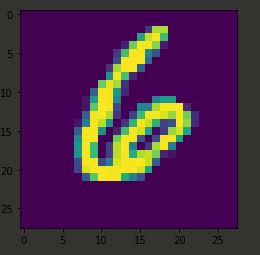
Ну а теперь нам бы хотелось увидеть содержимое этих списков , но в понятном виде , а не в виде длинного списка с набором чисел. Для этого используем ранее подключенную библиотеку matplotlib. Выведем на экран произвольный элемент из набора , допустим 13-й
## plt.imshow(X_train[13]) plt.show()
и что мы видим!! Содержимое 13 го элемента нашей подгруженной базы. Если все выполнили правильно , сможете наблюдать отрисовку рукописной цифры 6.
На этом наша первая статья по распознаванию рукописного текста завершена , мы немного узнали о том , какие библиотеки ключевые , и какие нам понадобятся для визуализации содержимого различных баз. В следующей статье речь пойдет о построении модели нейросети.